
The natural language reasoning abilities of modern large language models (LLMs) have meant that machine learning can finally be applied to mundane business applications. This development has spurred the emergence of chatbots such as OpenAI’s ChatGPT. These models are trained on vast amounts of data, making them excellent at getting quick answers to questions you might have while programming or writing up a document. That tool is valuable, but their semantic understanding can be taken further. In this post, I will walk you through how we implemented an LLM-powered chatbot in our existing company chat interface and extend it beyond the Q&A of its internal knowledge base.
To motivate the need for custom behaviors, consider the following (real) situation. Whenever we start a new project, whether client-facing or internal, a private channel is created for it in Mattermost (our self-hosted chat platform of choice). With multiple team members working on different parts of the project, these channels can quickly grow beyond a length that is easy to ingest in a moment or two. This presents a problem for those who joined the project late, missed a few days, or management looking for a status update and project overview. Wouldn’t it be great if we could generate daily, weekly, and all-time channel summaries to condense all this chatter into something that could be read in a minute? This was precisely the motivation behind the creation of our chatbot, George.
The first hurdle in getting George up and running was having a way to execute code via messages sent in Mattermost. For this, we used the open-source bot client Errbot, which allows the creation of bot commands like !summarise day, which begin with an exclamation mark. We tapped into the natural language reasoning abilities of LLMs via the AWS Bedrock API. This serverless offering takes an API request containing a prompt, a choice of model, and a handful of parameters and returns the generated response. This barebones setup was enough to implement simple methods, such as !ask [query] to replicate simple Q&A in our chat interface.
Extending the abilities of our bot, George, required the addition of a message history. By creating a message history separate from Mattermost’s internal one, we avoided the security concerns that come with giving the bot the ability to scrape the Mattermost server. Instead, only messages George sees (sent to channels he has been added) are pushed to the bot’s message history. The history was implemented using AWS DynamoDB, another serverless offering which manages a NoSQL database.
With all the pieces in place, we could now write python to handle a !summarise day command by:
- Retrieving all messages sent to the channel in question within the last day from DynamoDB.
- Collecting them into a prompt easily interpretable by an LLM and wrapping it with instructions on what we want it to do.
- Querying the Bedrock API and
- Posting the resulting summary to the channel.
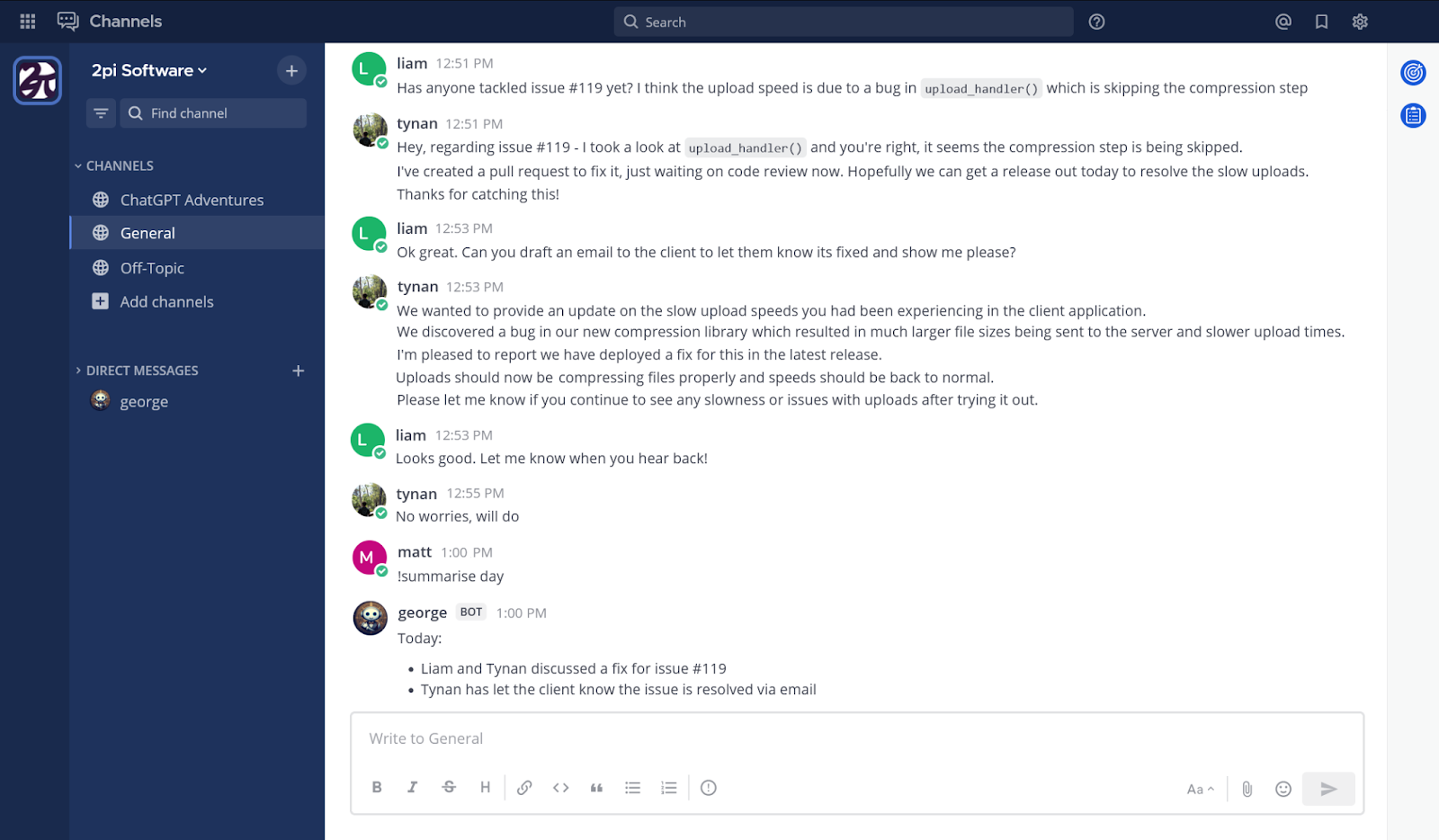
A simple example of the summary command in action can be seen below.
The history retrieval we used in the summary command is similar to a standard pattern called retrieval-augmented generation, or RAG, where we retrieve relevant information to include in the prompt to the LLM to enhance the quality of the response. Unlike our message retrieval method, where all messages are sorted by channel and ordered by timestamp, RAG is usually used over large, unstructured bodies of data. To find relevant chunks at query time, a measure of similarity to the user’s question is needed. For this, the chunks are embedded into a numerical representation before being stored. When a user asks a query, we can numerically compare the representation of the question to that of each piece of text in the database. The few most similar chunks are tacked onto the end of the prompt to give the LLM some extra information to help it provide an accurate answer.
AWS Infrastructure elements and flow for document chat/summarisation commands
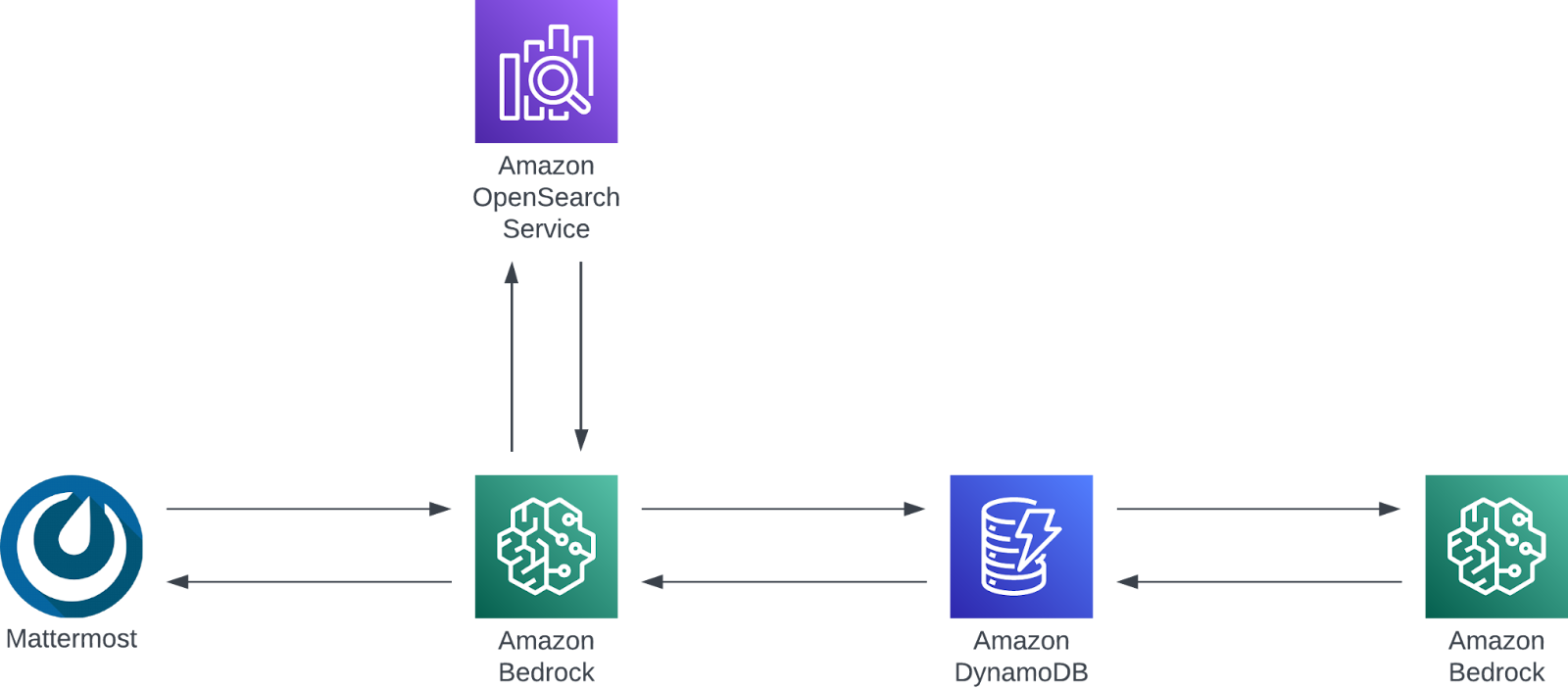
A second command we built into George is !doc chat, which takes an uploaded document (.pdf, .docx, .txt, …) and allows you to ask questions about its content. This was achieved using a combination of the RAG and message history retrieval patterns mentioned earlier. Upon receiving the command, George embeds the document to AWS OpenSearch and awaits further instruction. This is one of a few commands that enter a context mode, meaning that George will interpret all queries about the document until we tell him we’re done. By entering a context mode, we can rapidly fire off questions about the document’s content without having to let George know each time where to look for the answers (eg. Search the document for the answer to…).
Armed with these bespoke commands tailored to our needs, George brings the benefits of LLMs closer to where we already work every day and solves existing inefficiencies rather than creating new ways of doing things. As new wants and needs arise, the bespoke chatbot system we have created will be poised to adapt to meet them quickly.